When I first started building numpy-ts, everybody said there was no way it could reach performance parity with NumPy’s native implementation and its decades of optimization.
I set out to prove those naysayers wrong.
Turns out, they were right.
Pure JavaScript/TypeScript was never going to match NumPy on raw numerical performance. Not for the operations where NumPy is really not “Python” anymore, but C, BLAS/LAPACK, pocketfft, and a very mature memory model, all hiding behind a Python API.
The path to making numpy-ts competitive with native NumPy was not making JS magically faster. It wasn’t even “use WASM,” at least not on its own. It was changing who owned the bytes.
Functional parity was the easy part
The first major goal for numpy-ts was compatibility. I wanted something that felt like NumPy, worked naturally in TypeScript, and sported the same API surface as Python NumPy.
After several months, numpy-ts reached broad functional parity, with comprehensive API coverage and strong cross-validation test suites. You could write NumPy-style code in TypeScript and get the right answers.
It was also painfully slow.
At that stage, numpy-ts was roughly 15x slower than native NumPy across the benchmark suite.
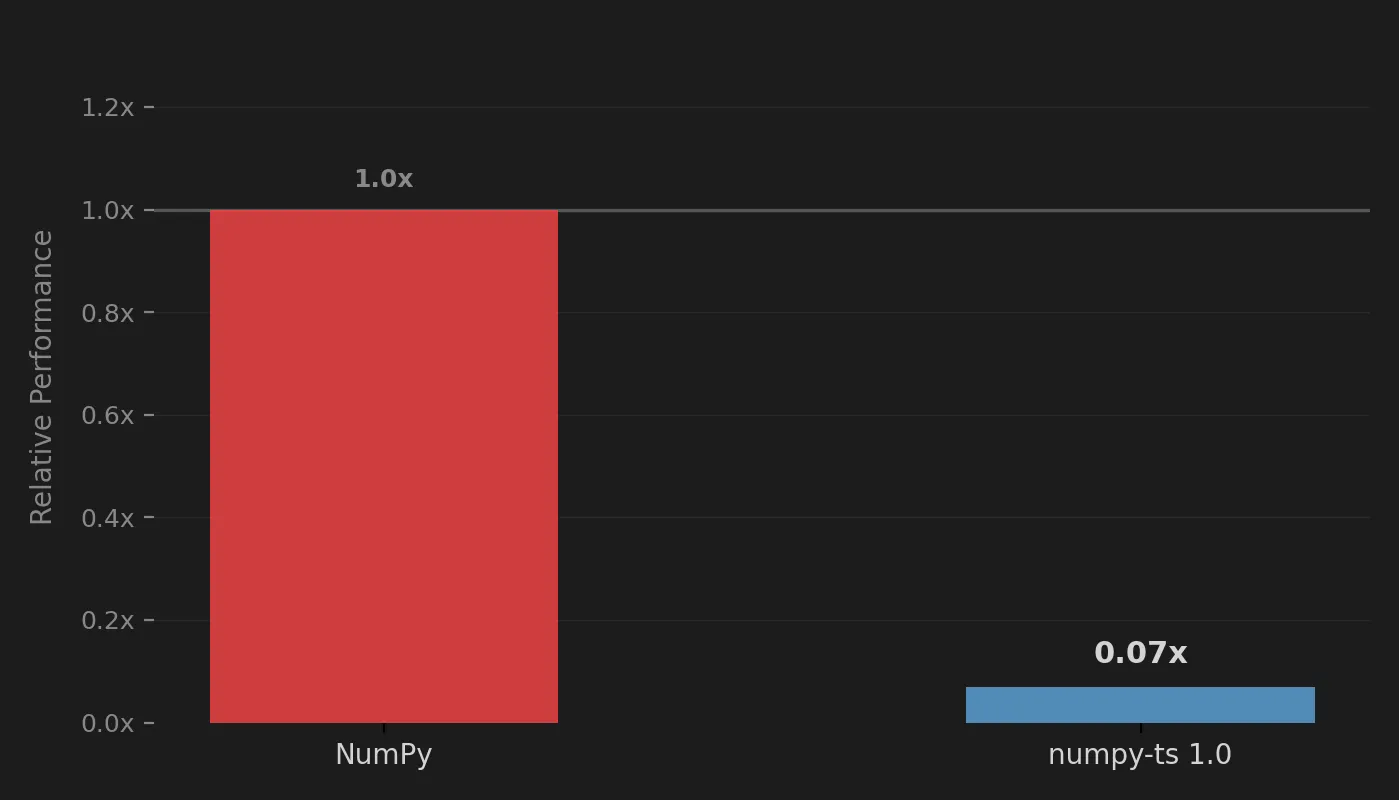
This was not because JavaScript engines are bad. V8, JavaScriptCore, and other modern runtimes are extraordinary pieces of engineering, and they handle exactly this shape of work well. A tight, monomorphic loop over a contiguous Float64Array compiles to something pretty close to the equivalent scalar loop in C.
The problem is that scalar C is not the bar. NumPy isn’t running scalar loops. Its hot paths are SIMD-vectorized, dispatch into mature kernels like BLAS, LAPACK, and pocketfft, and in places parallelize across cores. Portable JavaScript can’t express most of that: no explicit SIMD, no native BLAS, and every number is a float64. So even a perfectly JIT-compiled JS loop ends up competing one lane at a time against kernels doing four, eight, or sixteen.
For small operations, where that vectorization advantage barely matters and fixed overheads dominate, JavaScript could be surprisingly competitive. For large arrays and compute-heavy kernels, where NumPy’s vectorized, specialized machinery is doing real work, it could not keep up.
The obvious next step was WebAssembly.
WASM kernels: good, but not a silver bullet
The first instinct was simple: move the slow functions to WASM.
That was directionally right, but there was an important constraint. I did not want numpy-ts to become one giant native blob. It still needed to feel like a TypeScript library:
- tree-shakeable (small when you only import a few functions)
- ergonomic from JavaScript
- portable across Node, Bun, Deno, and browsers
So instead of rewriting the entire library in native code, I opted to move performance-critical kernels into small, self-contained WASM modules.
I found Zig to be a good fit for this problem. Zig can produce small WASM artifacts, has no mandatory runtime, gives direct control over memory, and is pleasant for writing the kind of low-level loops numerical kernels need.
This helped a lot. The performance gap dropped from about 15x slower than NumPy to roughly 2x slower.
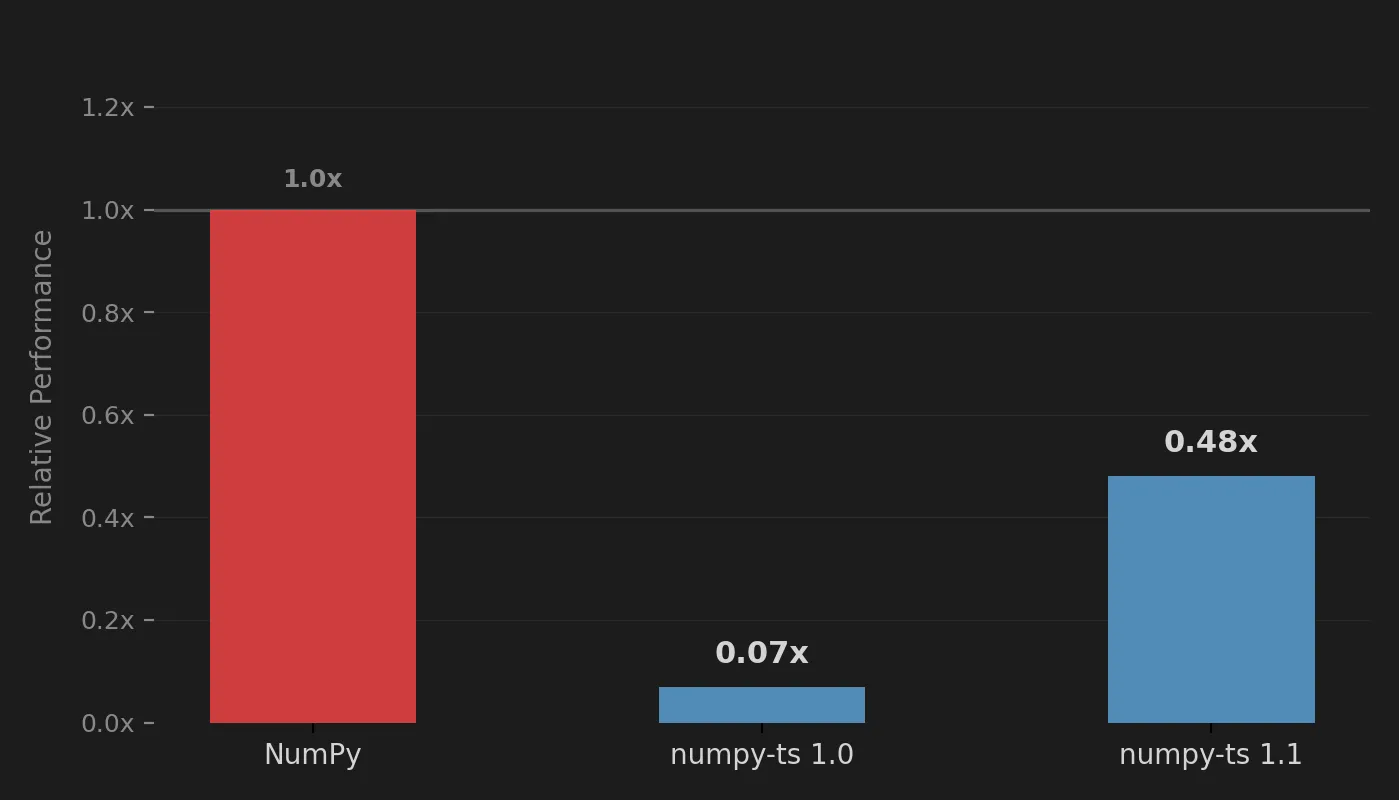
At this point, many of the expensive loops were already running in compiled WASM. The kernels themselves were fast, but 50% native speed appeared to be a ceiling. Why was that?
My first suspicion was FFI overhead. Maybe calling into WASM was just too expensive. Maybe the boundary between JavaScript and WASM was the bottleneck. Maybe lots of small native calls were killing performance.
Modern JS engines have done a lot of work to make WASM calls and execution fast. SpiderMonkey, for example, optimized call overhead between JS and WASM years ago, while V8 has continued pushing WASM optimization further with work like speculative inlining and deoptimization support.
In my case, the remaining gap was not explained by call overhead alone.
The real problem was the copy.
In my initial approach, the ndarray data lived in JavaScript-owned TypedArray objects. When numpy-ts needed to run a WASM kernel, it had to copy data into WASM linear memory, run the kernel, then copy the result back out into JavaScript memory.
For an isolated operation, this was tolerable. For NumPy-style code, it was disastrous.
Numerical programs are full of chained operations. Add, multiply, reshape, reduce, broadcast, slice, take, compare, accumulate. If every operation pays a copy-in/copy-out tax, then the actual computation is no longer the only thing being benchmarked. In many cases, it isn’t even the dominant cost.
The missing element: no-copy calls
Instead of storing ndarray data in JavaScript and copying it into WASM for computation, what if we moved storage into WASM linear memory?
JavaScript still owns the high-level object model: shapes, strides, dtype metadata, method chaining, API ergonomics, and TypeScript types. But the bytes backing an array live in WASM memory.
With this approach, a kernel no longer needs to copy inputs into WASM memory, because the inputs are already there. It no longer needs to copy outputs back into JavaScript memory, because outputs can also be allocated in WASM memory. JavaScript can pass pointers and metadata instead of moving entire buffers around.
This sounds obvious in hindsight, but it is a much deeper architectural change than “use WASM.”
Once WASM owns the array data, you need a memory model. You need allocation and deallocation. You need to think about fragmentation, lifetimes, views, slices, and what happens when JavaScript objects are garbage collected but their underlying WASM allocations are not.
For numpy-ts, that meant building a custom allocator for WASM linear memory. The allocator uses a segregated free list, which is a good fit for ndarray workloads because arrays tend to allocate and free blocks across a range of common sizes. It avoids turning every array allocation into a slow path and makes it practical for many arrays to live entirely inside WASM memory.
That was the architectural turning point. On the same benchmark suite, numpy-ts finally reached native NumPy performance.
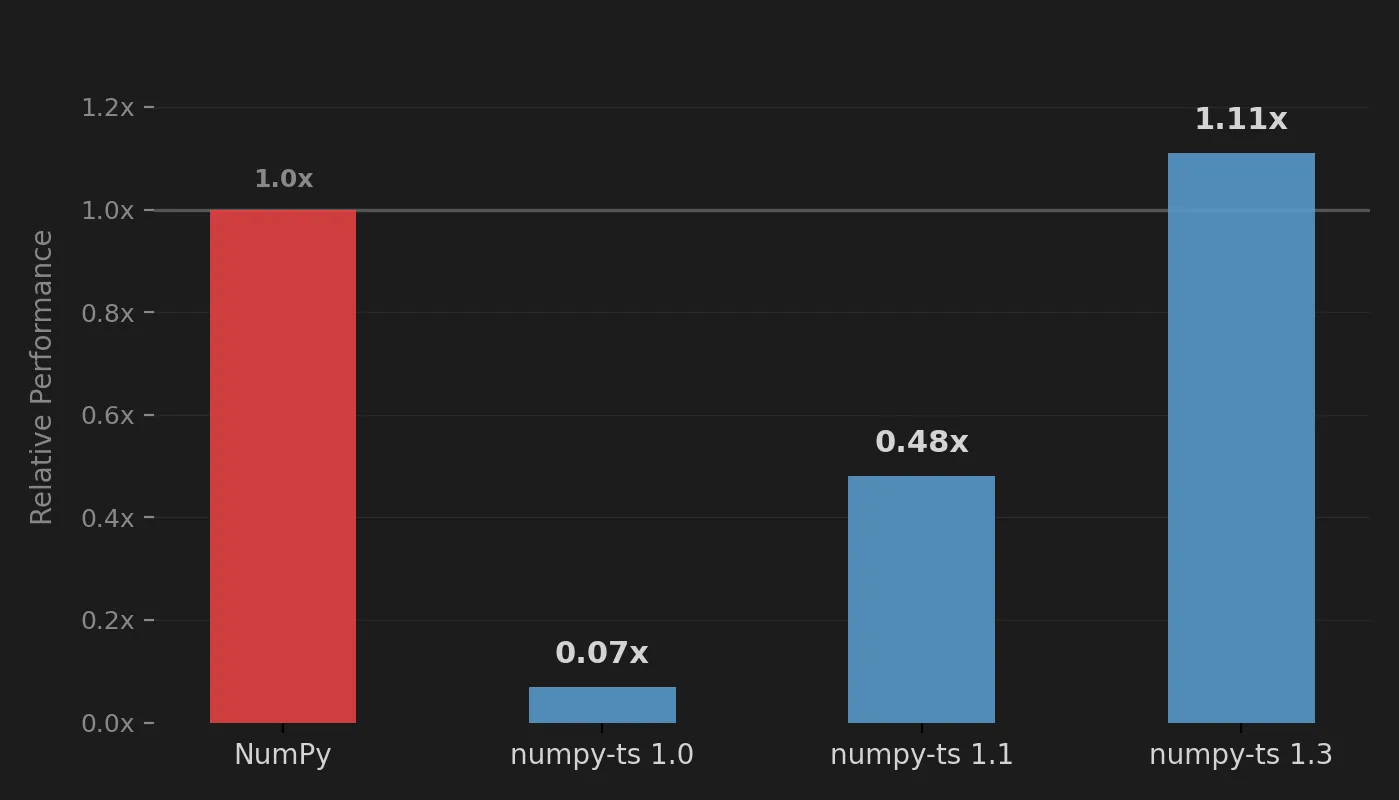
The reason it pulled ahead is that numpy-ts no longer pays a copy tax on every WASM call. That matters most in ordinary NumPy-style code, where operations chain:
const y = np.sin(x)
.add(np.square(x))
.multiply(0.5)With WASM-owned arrays, those intermediates stay in one memory space instead of bouncing between two heaps on every step.
Benchmark results
After these optimizations, numpy-ts is on average 1.11x faster than native NumPy across 7,159 benchmarks on an Apple M4 Max. That average is a geometric mean across operations, dtypes, and array sizes.
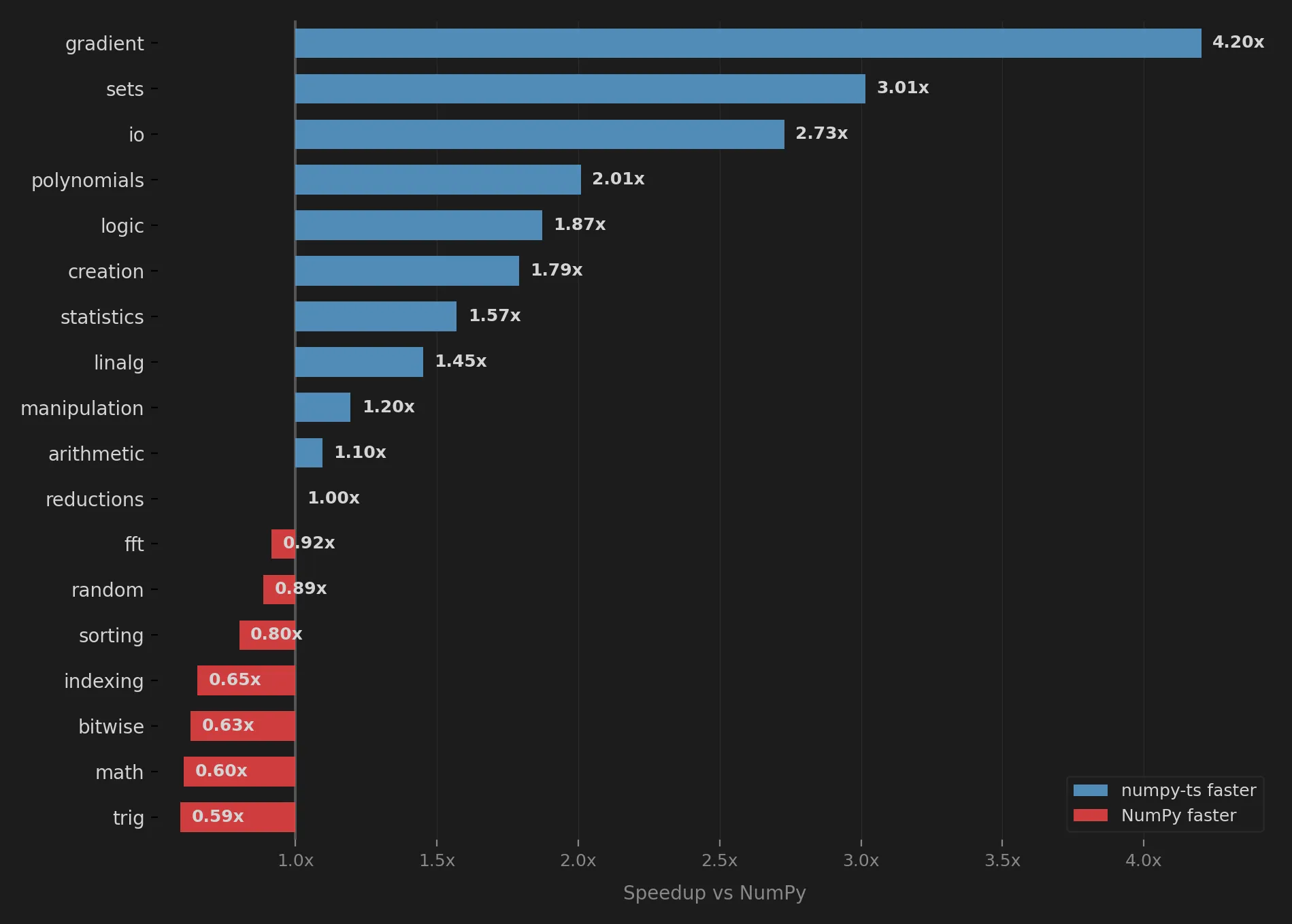
The suite covers 308 benchmark specifications across 18 categories, producing 7,159 benchmark results across operations, dtypes, and sizes. NumPy benchmarks run in Python, and numpy-ts benchmarks run in Node.js, so the comparison does not depend on calling one runtime from the other.
You can read the full benchmark methodology and all benchmark results. There are also separate breakdowns for size scaling and Node/Bun/Deno runtime comparisons.
numpy-ts is not faster than NumPy in every category. NumPy still wins in several areas, including some math functions, trigonometry, indexing-heavy workloads, sorting, random generation, FFTs, and complex dtype operations.
The tradeoffs
Moving array data into WASM memory fixed the biggest performance bottleneck, but it also made numpy-ts more complicated.
That is the general pattern with this kind of work. The closer you get to native performance, the more you inherit native-style problems.
Tradeoff #1: memory management
When array data lives in JavaScript typed arrays, the garbage collector manages memory. You can create arrays, drop references, and trust the runtime to eventually clean up.
When array data lives in WASM linear memory, that is no longer enough. A JavaScript NDArray object may be garbage collected, but the WASM allocation it points to does not automatically disappear unless the library arranges for that to happen.
FinalizationRegistry helps with automatic cleanup, but it is intentionally nondeterministic. That is fine for casual use, but not enough for long-running numerical workloads where memory pressure needs to be predictable.
numpy-ts also supports deterministic cleanup through JavaScript’s using pattern via Symbol.dispose. Casual users can mostly ignore memory management; serious users can release temporary arrays explicitly when they need to.
Under the hood, numpy-ts still has to track ownership carefully so that views, slices, and derived arrays do not free memory too early or leak it forever.
Tradeoff #2: dtype support
NumPy has decades of machinery around dtypes. WASM does not map perfectly onto that world. float16 is a good example: there is no universally available native WebAssembly f16 path that numpy-ts can rely on across runtimes today, so float16 values have to be represented as uint16 where possible and promoted to float32 for computation when necessary.
It’s workable, but it is not free.
Tradeoff #3: packaging
numpy-ts needs to work in Node, Bun, Deno, browsers, test runners, bundlers, CDNs, and tree-shaken npm installs. Those environments do not all agree on how .wasm files should be loaded. Some expect asset URLs, some inline them, some require async initialization, some behave differently under ESM, etc.
For numpy-ts, the practical solution was to compile each Zig kernel to WASM, encode the module as base64, and inline it into a generated TypeScript file. That is not the prettiest artifact, but it gives users a normal ESM module, avoids separate asset loading, keeps kernels self-contained, and lets bundlers tree-shake unused kernels, all transparently.
What I learned
The obvious story is that WASM made numpy-ts fast. But it’s only half true.
WASM made it possible to write fast kernels. But the first WASM architecture still could not reach native performance because it moved too much data. The real breakthrough was changing the ownership model: ndarray data had to live where the kernels run.
numpy-ts is still young. There are categories where NumPy is faster, kernels that need work, and plenty of architecture left to build.
The skeptics were right about the original design. Pure TypeScript was not going to beat native NumPy.
The part I missed was that “native performance” was less about where the arithmetic ran, and more about where the data lived.
Once that changed, the performance work started to look much less impossible.